Project Sodinokibi
Malware Bazaar and VirusTotal platforms revealed some interesting insights into who manages Sodinokibi, from the perspective of incident response.

Learning Python
Python is the language I always wanted to learn. I tried but failed every single time, don't know exactly why. This time was different though, I knew from the first line of code. So, with a little push of a dear friend of mine (thanks Elio!), I tried to investigate how to decode Sodinokibi ransomware configurations for hundreds, maybe thousands, of samples. I intended to understand, using powerful insights from VirusTotal Enterprise API, if there are relationships between Threat Actor, mapped inside the ransomware configuration, and the country visible from the VirusTotal sample submission.
I am perfectly aware that it's not as easy as it seems: the ransomware sample submission's country, visible from VirusTotal, may not be the country affected by the ransomware itself. But, in one case of another, I think there could be somehow a link between the two parameters: maybe from the Incident Response perspective.
Getting the samples
My first step was to get as many samples as I could. My first thought was to use VirusTotal API: I'm lucky enough to have an Enterprise account, but the results were overwhelming and, due to the fact I was experimenting with Python, the risk of running too many requests and consume my threshold was too high. So I opted to use another excellent malware sharing platform: Malware Bazaar by Abuse.ch
All the code is available here
downloaded_samples = []
data = { 'query': 'get_taginfo', 'tag': args.tag_sample, 'limit': 1000 }
response = requests.post('https://mb-api.abuse.ch/api/v1/', data = data, timeout=10)
maldata = response.json()
print("[+] Retrieving the list of downloaded samples...")
for file in glob.glob(SAMPLES_PATH+'*'):
filename = ntpath.basename(os.path.splitext(file)[0])
downloaded_samples.append(filename)
print("[+] We have a total of %s samples" % len(downloaded_samples))
for i in range(len(maldata["data"])):
if "Decryptor" not in maldata["data"][i]["tags"]:
for key in maldata["data"][i].keys():
if key == "sha256_hash":
value = maldata["data"][i][key]
if value not in downloaded_samples:
print("[+] Downloading sample with ", key, "->", value)
if args.get_sample:
get_sample(value)
if args.clean_sample:
housekeeping(EXT_TO_CLEAN)
else:
print("[+] Skipping the sample because of Tag: Decryptor")This block of code essentially builds the request for the back-end API where the tag to search for comes from the command line parameter. I defaulted it to Sodinokibi. It then creates a list of samples already present in the ./samples directory not to download them again. Interestingly, because there are many Sodinokibi decryptors executables on the Malware Bazaar platform, I needed some sort of sanitization not to download them. When it founds a sample not present inside the local directory, It then calls the function to download it.
def get_sample(hash):
headers = { 'API-KEY': KEY }
data = { 'query': 'get_file', 'sha256_hash': hash }
response = requests.post('https://mb-api.abuse.ch/api/v1/', data=data, timeout=15, headers=headers, allow_redirects=True)
with open(SAMPLES_PATH+hash+'.zip', 'wb') as f:
f.write(response.content)
print("[+] Sample downloaded successfully")
with pyzipper.AESZipFile(SAMPLES_PATH+hash+'.zip') as zf:
zf.extractall(path=SAMPLES_PATH, pwd=ZIP_PASSWORD)
print("[+] Sample unpacked successfully")A straightforward function: builds the API call, gets the zipped sample, unpack, and saves it inside the directory ./samples. Note that the sample filenames are always their SHA-256 hash. After unpacking it, I made a small housekeeping function to get rid of the zip files.
def housekeeping(ext):
try:
for f in glob.glob(SAMPLES_PATH+'*.'+ext):
os.remove(f)
except OSError as e:
print("Error: %s - %s " % (e.filename, e.strerror))This is what happens when you run the script.
Getting insights on ransomware configuration
Now it's time to analyze these samples to get the pieces of information we need. The plan is to extract the configuration from an RC4 encrypted configuration stored inside a PE file section. Save ActorID, CampaignID, and executable hash. With the latter, we then query VirusTotal API to get insights for the sample submission: the City and the Country from where the sample was submitted and when there was the submission. As I wanted to map these pieces of information on a map, with OpenCage API I then obtained cities coordinates of the submissions.
The code to build the API calls and parse the response JSON is rough, shallow and straightforward I would not go with it. I'm sure there are plenty of better ways to do its job, but...it's my first time with Python! So bear with me, please. What I think it's interesting is the function that extracts and decrypts the configuration from the ransomware executable PE file. These are the lines of code that do this task:
excluded_sections = ['.text', '.rdata', '.data', '.reloc', '.rsrc', '.cfg']
def arc4(key, enc_data):
var = ARC4.new(key)
dec = var.decrypt(enc_data)
return dec
def decode_sodinokibi_configuration(f):
filename = os.path.join('./samples', f)
filename += '.exe'
with open(filename, "rb") as file:
bytes = file.read()
str_hash = hashlib.sha256(bytes).hexdigest()
pe = pefile.PE(filename)
for section in pe.sections:
section_name = section.Name.decode().rstrip('\x00')
if section_name not in excluded_sections:
data = section.get_data()
enc_len = struct.unpack('I', data[0x24:0x28])[0]
dec_data = arc4(data[0:32], data[0x28:enc_len + 0x28])
parsed = json.loads(dec_data[:-1])
return str_hash, parsed['pid'], parsed['sub']
#print("Sample SHA256 Hash: ", str_hash)
#print("Actor ID: ", parsed['pid'])
#print("Campaign ID: ", parsed['sub'])
#print("Attacker's Public Encryption Key: ", parsed['pk']) Disclaimer: these lines are, obviously, not mine. I modified the script provided by the guys of BlackBerry ThreatVector. I invite you to read where they explain how the configuration is stored within the section, where's the RC4 encryption key and how to decrypt it.
In my version of the script, it runs on Python3 and uses a standard library for the RC4 algorithm. Also, it's worth to mention that this script fails if input samples are packed. It expects the existence of the particular section with the saved encrypted configuration; it fails otherwise. I added some controls to handle miserable crashes, but there are unmanaged cases still: I'm so new to Python!
In the end, we have a dear old CSV file enriched with a bunch of information: Country, City, Latitude, Longitude, ActorID, CampaignID, Hash, Timestamp. We're ready to map it.
Understanding the data
Our data is described inside a data.csv
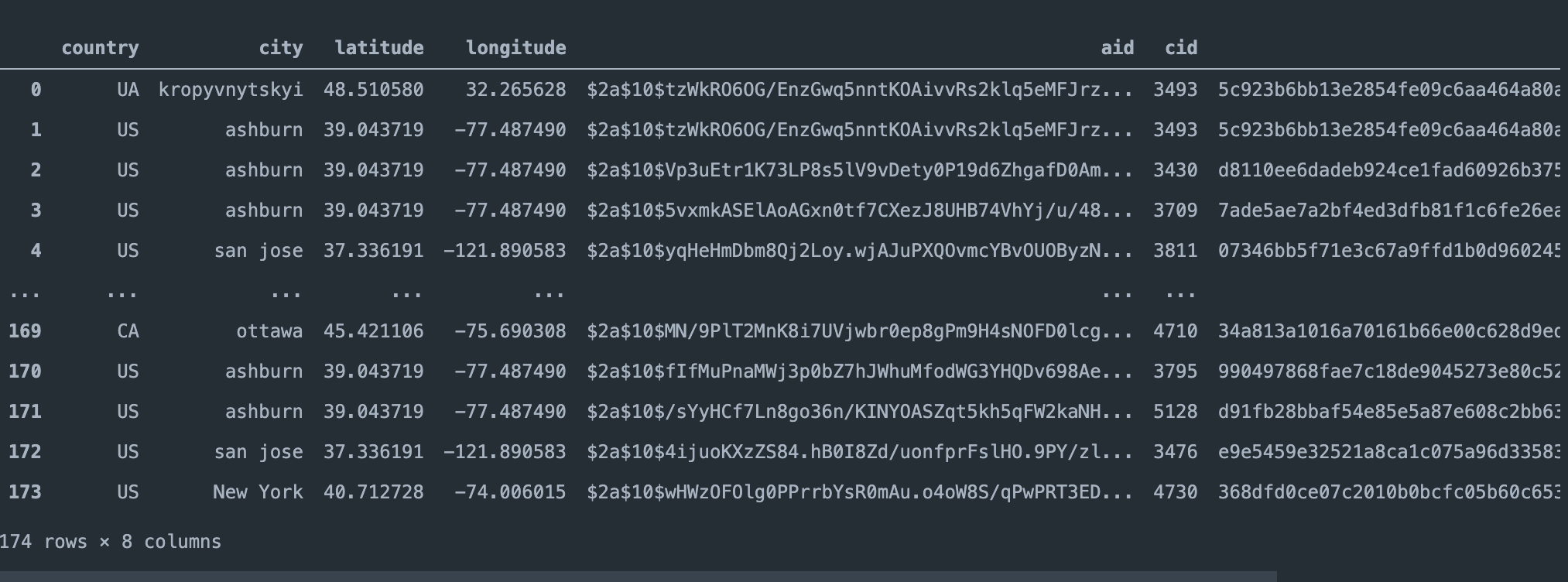
Field aid (ActorID) is changed, during the months, from an integer number, like ActorID: 39 to a hash representation. For now, we have only 174 samples where we managed to extract the configuration. We can now group the data by aid field and count the submissions.
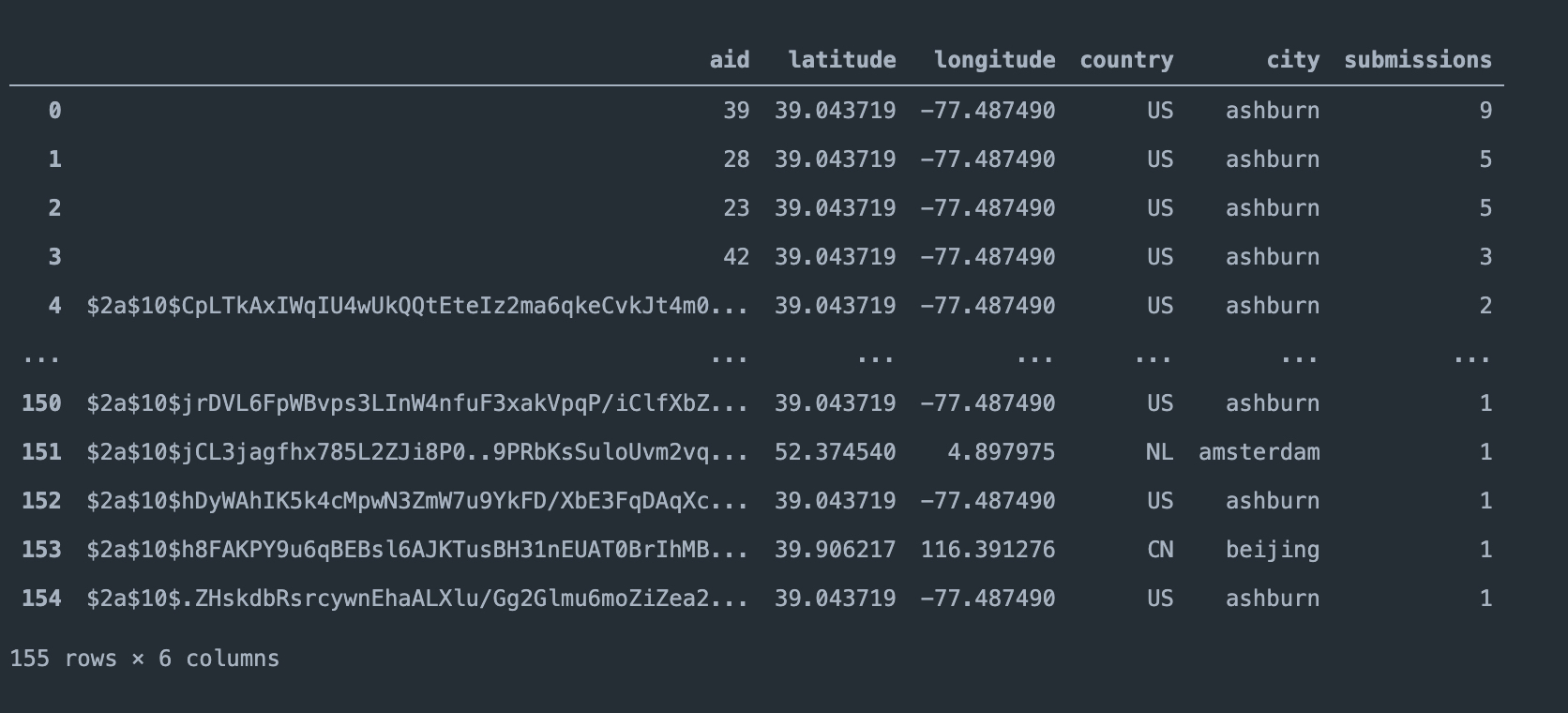
From what I see, I can understand that the samples related to ThreatActor with the ID 39 have nine submissions from the city of Ashburn US. I have to comprehend why this city has so many submissions related to Sodinokibi. I hope that someone that reads this post would help me to understand and shed some light.
If we map the ThreatActorID vs the City of the submission, we can easily see the data.
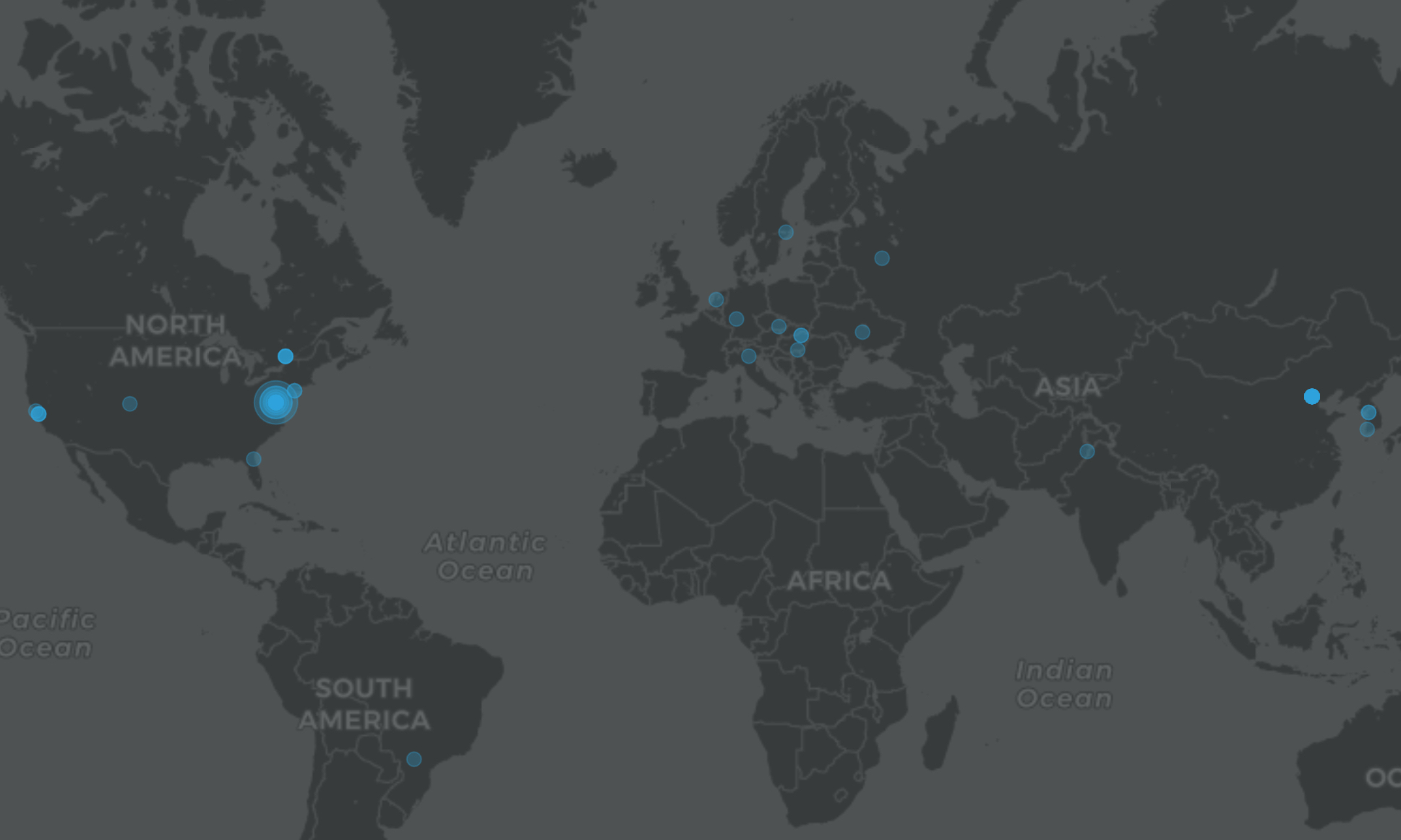
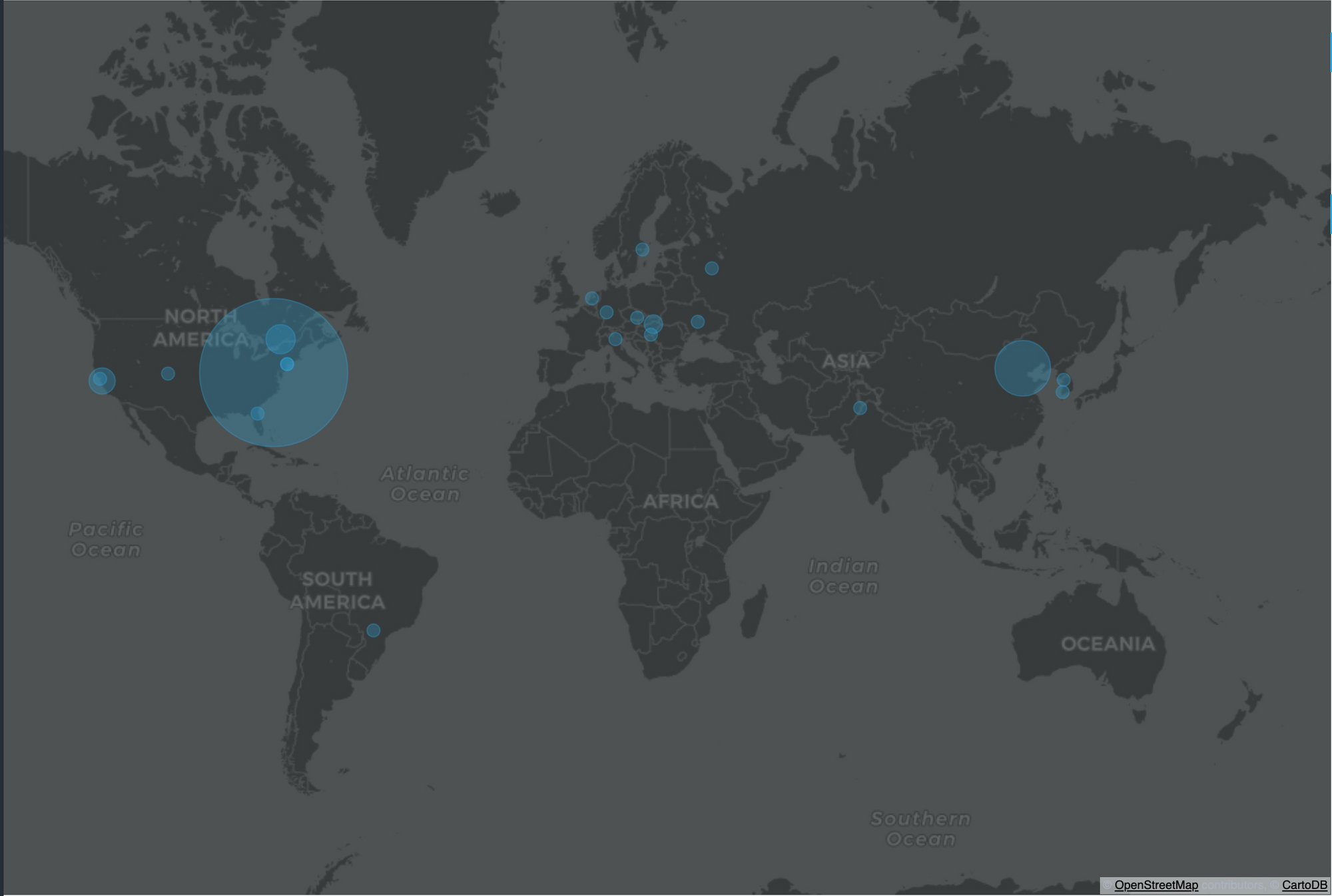
Next steps would be acquiring as many samples as I can. The best choice would be using VirusTotal API to retrieve the samples and this is what I'm going to do. Hopefully I won't burn my entire Company API limit.
All the scripts used in this post, the data and the Jupiter notebook used to map the data is available here.